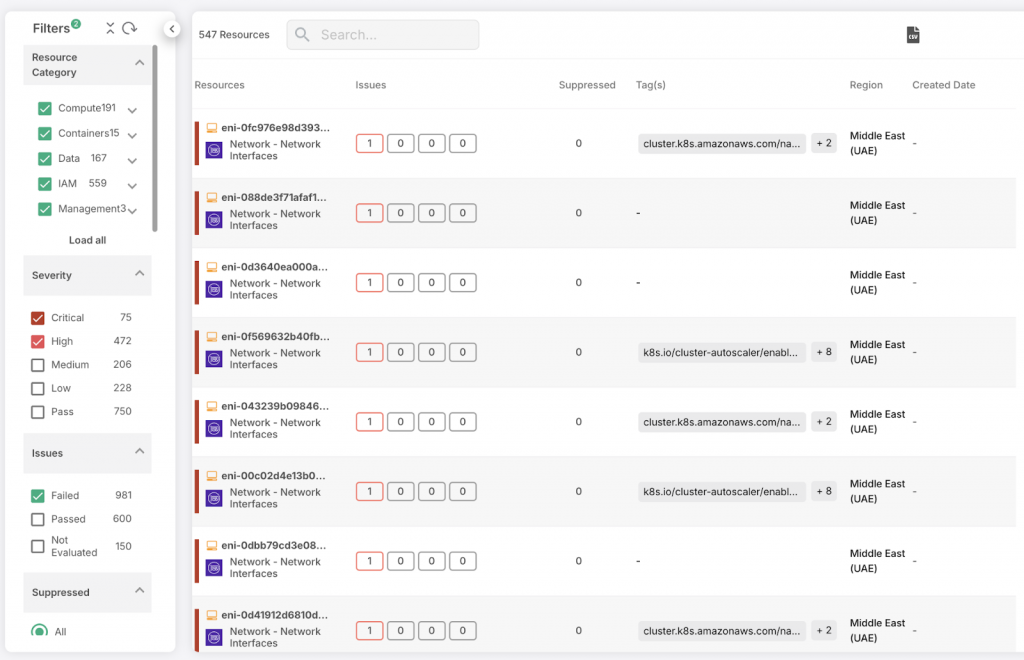
What is Data Classification?
Data Classification is the method of organizing data and then separating it into different classes if they have matching characteristics. Data is classified based on the criteria of sensitivity of the data, effects compliance regulation has on them, and the severity of the risks they present to the company if exploited.
Different data have different sensitivity levels. When companies classify them differently, it helps to understand the amount of access privileges they require and the security measures that need to be put in place to protect them.
However, companies need to pay more attention to its effectiveness when it comes to ensuring efficient data handling.
Why do we need to Classify Data?
Data classification is a fundamental practice in modern data management and security, helping organizations meet a range of operational, security, and regulatory needs. Effective classification enhances data accessibility by streamlining how information is organized, stored, and retrieved.
This need to be done while ensuring only authorized users can access sensitive data. This structured approach is especially critical for regulatory compliance, as many industries mandate that organizations retrieve specific data types within defined timeframes.
From a security perspective, data classification enables tailored protections based on the data’s sensitivity level. For instance, confidential data may require encryption, access controls, and stricter monitoring, while public data can be stored with fewer restrictions. By aligning security responses with the data type, organizations reduce risk and efficiently allocate resources.
Data Classification Example
Here’s a simple example of data classification for an organization:
Imagine a healthcare company managing patient records, internal reports, and general public health information.
- Public Data: The organization publishes health awareness content, industry reports, and general wellness tips for the public. This data is open for anyone to access and therefore classified as Low Risk. Since it is not sensitive and can be easily recreated, it does not need high security.
- Internal Use Data: The company has internal policy documents, non-sensitive financial records, and research that staff and certain partners access. While this information isn’t public, its compromise would have moderate impact, so it’s classified as Moderate Risk.
- Restricted/Sensitive Data: Patient health records, payment information, and any regulated medical data fall under High Risk. Due to legal obligations and patient privacy concerns, this data requires strong encryption, access controls, and regular audits to prevent breaches.
In this setup, the healthcare company prioritizes resources to protect high-risk data, follows moderate controls for internal data, and uses basic security measures for public information.
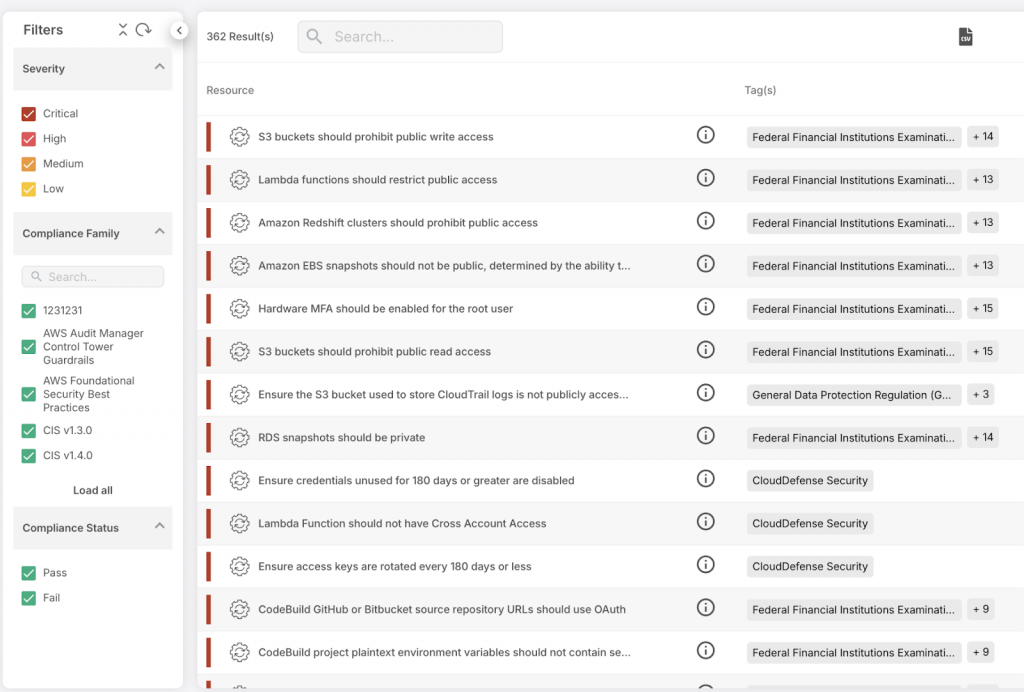
Types of Data Classification
There are three primary types of data classification methods. These include:

- Context-based Classification: This method classifies documents based on metadata from a few factors: The location or department from which the document has been created, the creator of the document, and the application used to create the document.
- Content-based Classification: This method checks for the content in a document and classifies it accordingly.
- User-based Classification: This method classifies documents based on the judgment of a user. Users rank the document according to a sensitivity scale.
What Forms of Data do Companies Handle?
Companies handle a variety of data types, each requiring different levels of protection. Here’s a quick breakdown:
- Public Data is freely available to everyone, like government reports and market research, and can be used without restriction.
- Internal Data includes company-specific information like memos and emails. It’s not highly sensitive but should still be protected to avoid moderate harm if exposed.
- Confidential/Restricted Data includes highly sensitive info, like government-classified data or patient records, which require strict protection due to legal and reputational risks.
- Sensitive Data is the most protected, including things like intellectual property and PHI, whose exposure could lead to significant harm or legal issues.
- Private Data is personal info, such as PII, which may or may not be protected by law but must be handled carefully.
- Proprietary Data includes trade secrets, business strategies, and R&D data—key to a company’s competitive advantage, so it requires tight security.
Each type of data demands customized security measures to ensure compliance and protect the organization from risk.
Labeling Data Risk
When classifying data, organizations need to evaluate the risk associated with each data type, how it’s managed, and where it’s stored or sent (such as endpoints). Typically, data and systems can be categorized into three risk levels:
- Low Risk: Public data that can be easily recovered if lost falls into this category. Since its loss would not impact operations significantly, it’s generally considered low risk.
- Moderate Risk: This includes data that is used internally but isn’t sensitive or essential to operations. Proprietary information, cost-related data, and some internal documents might be classified as moderate risk since they have value but aren’t critical.
- High Risk: Sensitive or crucial data for business operations, especially information that is difficult to recover if compromised, is placed in the high-risk category. Confidential, sensitive, and vital data all belong here due to their operational importance and security implications.
Note: Some organizations opt for more detailed scales, adding categories like “severe” risk to further distinguish critical data and system security levels.
Benefits of Data Classification
Looking at the recent surge in customer data breaches, it has become hard for companies to secure customers’ trust in their services. It has become imperative for companies to get security features such as Data Classification to help build up trust in their clients and partners.
Data classification ensures the security, confidentiality, and privacy of data. Data security, in turn, plays a prominent role in attaining compliance against top industry security standards. Compliance is your certification to your customers and partners, assuring them that you are safe to get involved with and they can trust their sensitive data with you.
It is not only a great way to boost business but also to save on data storage costs since unorganized data can spike storage costs.
Methods of Data Classification
Data Classification can be obtained through three different methods,
- Manual Classification: Manual Classification provides the power of classifying data and enforcing it at the hands of humans.
- Automated Classification: Classifications by humans possess risks of misjudgment, therefore, technological solutions are used to classify data. This also helps in automating the whole process of data classification.
- Hybrid Classification: This method is a combination of both human intervention and technological processes. Making it error-free and efficient at the same time.
Tools Used for Data Classification
Data classification relies on various tools and technologies, including databases, business intelligence (BI) software, and conventional data management systems. A notable BI software example for data classification is the one provided by CloudDefense.AI.
CloudDefense.AI’s BI methods empower companies to efficiently categorize and manage their data, ensuring that it aligns with their security and compliance goals. You can book a complimentary demo to learn more about our services.
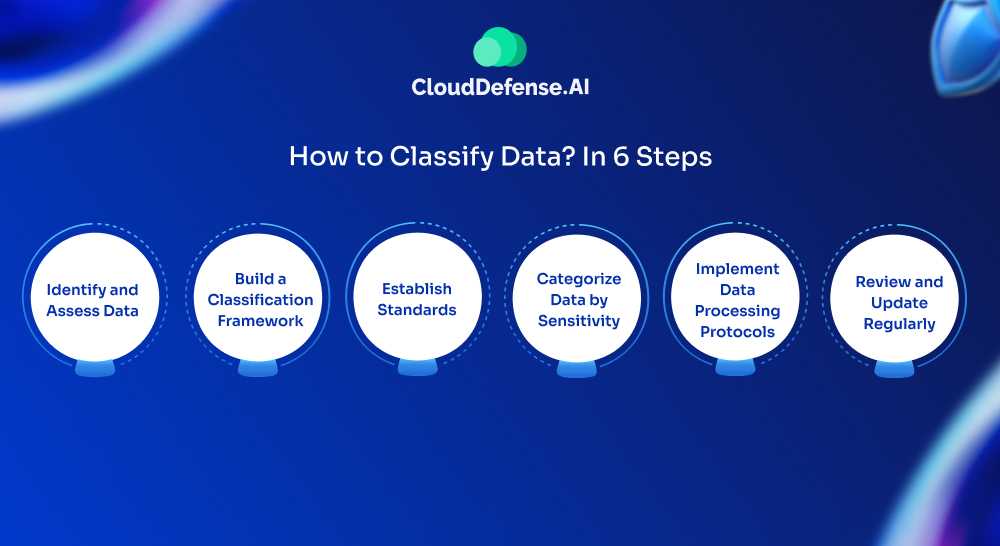
How to Classify Data? In 6 Steps
Not every piece of data needs to be retained or classified—sometimes the best course of action is to destroy unnecessary data. Understanding why and when data should be classified is crucial to creating a practical data governance strategy.
Here are six key steps for developing effective data classification policies:
- Identify and Assess Data
Start by pinpointing the data that requires retention and classification. Assess its value, location, access permissions, and whether multiple copies exist. Understanding these elements helps prioritize which data needs to be managed. - Build a Classification Framework
Collaborate with data experts to design a structured framework for data organization. This framework should include metadata tags or labels, making it easier for systems to recognize and categorize data efficiently. Tags can include details such as file type, data size, or character set. - Establish Standards
Align data classification practices with internal data handling policies and industry standards. Standards should address regulatory requirements, customer expectations, and protocols to prevent unauthorized exposure of sensitive data, such as personal health information or biometrics. - Categorize Data by Sensitivity
Label data according to its sensitivity level—like confidential, internal, or public—to enable quick identification and proper handling. This categorization helps to ensure sensitive data is better protected and managed in compliance with data security policies. - Implement Data Processing Protocols
Apply the classification framework in a way that databases and systems can automatically sort and recognize each data category. This step simplifies data management and ensures that each data item is accurately processed and stored. - Review and Update Regularly
Data classification is not static. Regularly update classifications and policies to keep up with evolving data regulations, organizational changes, and new data types. This ensures that your classification strategy remains current and compliant over time.
These steps provide a foundation for building a comprehensive data classification approach that protects valuable information and streamlines data management.
What Is GDPR Data Classification?
GDPR Data Classification is the process by which organizations identify, categorize, and safeguard personal data according to the standards set by the General Data Protection Regulation (GDPR).
Under GDPR, any data that could directly or indirectly identify an individual—such as name, ID number, location data, or even online identifiers—must be classified as personal data and treated with strict protections.
Implemented on May 25, 2018, GDPR established a global standard for data protection, empowering individuals with rights over their personal data. This includes rights to access, correct, delete, and control the processing of their information.
Organizations must gain explicit user consent before data collection, appoint Data Protection Officers, report breaches promptly, and consistently demonstrate secure and compliant data practices.
Through GDPR-compliant data classification, organizations ensure their data processing aligns with privacy mandates, significantly enhancing data protection and accountability across the EU and worldwide.
Conclusion
As our reliance on data grows, the importance of data classification becomes even more essential. It is the foundation for securing sensitive information, respecting privacy, and enabling data-driven decision-making. Therefore, a robust data classification framework should be an integral part of any data management strategy, allowing organizations to harness the power of their data while maintaining the highest levels of security and compliance.








